We show the demo of DiffBeautifier:Fast Diffusion Model for High-Fidelity Singing Voice Beautifying
Overview
Singing voice beautifying (SVB) is a novel task that is widely used in practical scenarios. SVB task aims to correct the pitch of the singing voice and improve the expressiveness without changing the timbre and content. The major challenge of SVB is that paired data of professional songs and amateur songs is hard to obtain and we solved it for the first time. In this paper, we propose DiffBeautifier, an efficient diffusion model for highfidelity Singing Voice Beautifying. Since there are no paired data, diffusion model is adapted as our backbone, which is combined with modified conditions to generate our mel-spectrograms. We also reduce the number of steps of sampling t by using generator-based methods. For automatic pitch correction, we establish a mapping relationship from MIDI, spectrum envelope to pitch. To make amateur singing more expressive, we propose an expression enhancer in the latent space to convert the amateur vocal tone to the professional one. Furthermore, we produced a 40-hour singing dataset that contains original song vocals and extremely amateurish samples to promote the development of SVB. DiffBeautifier achieves a state-of-the-art beautification effect on both English and Chinese songs. Our extensive ablation studies demonstrate that expression part and generator-based methods in DiffBeautifier are effective.
Model Architecture
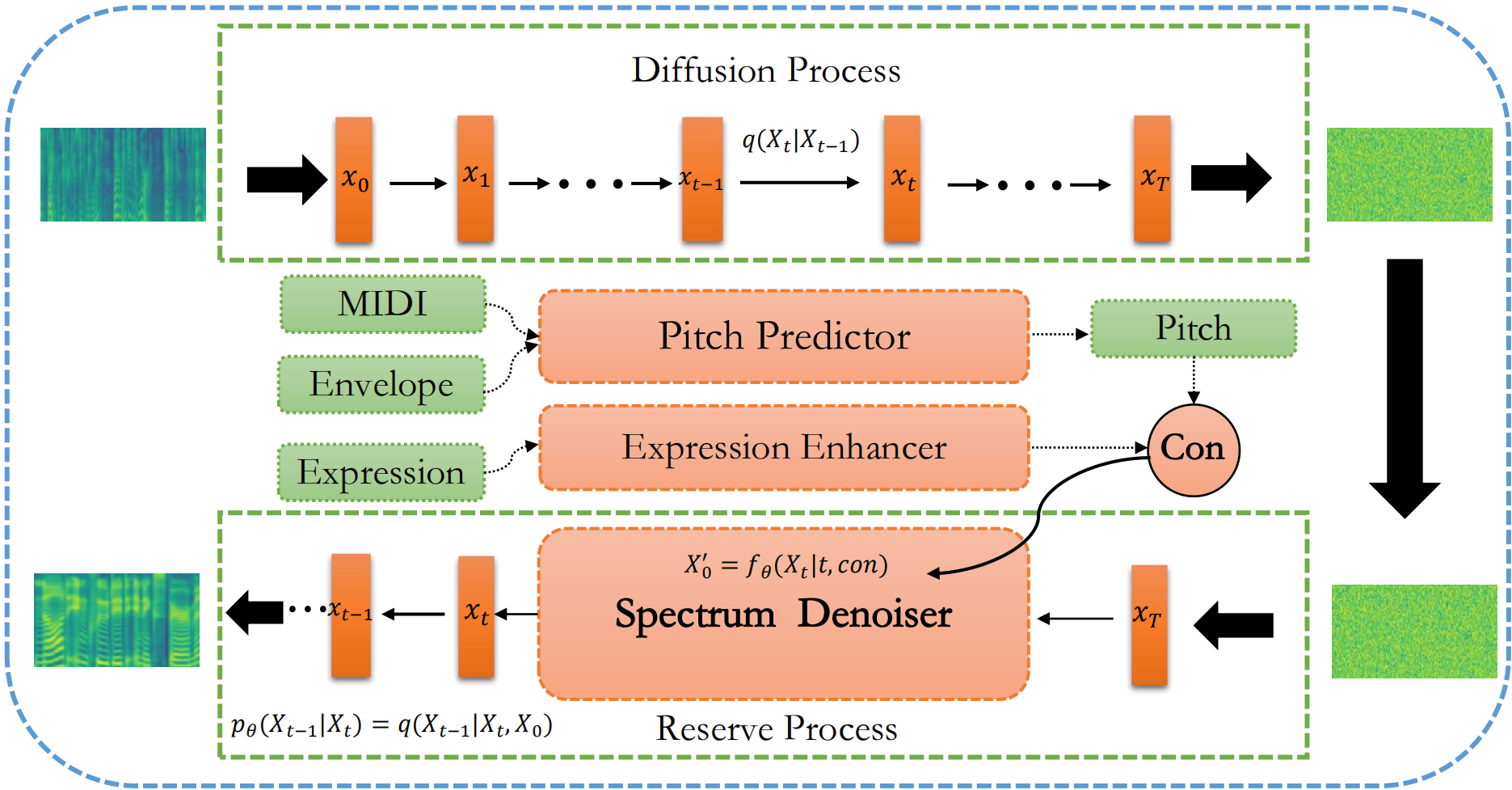 |
Figure.1 The overall architecture of DiffBeautifier.
Singing Audio Samples
There are four models in total: 1) GTMel, amateur (A) and professional (P) version, where we first convert ground truth audio into mel-spectrograms, and then convert the mel-spectrograms back to audio according to the vocoder. 2) Pitch Predictor, we first use the MIDI of the original singer, spectral envelope of amateur singing to predict our pitch curve. And then the predicted pitch curve, the spectral envelope of the amateur singing voice, and the aperiodic parameter of the amateur singing voice are used to synthesize the audio through the World Vocoder. 3)DiffBeautifier, this is the model proposed in this paper. All four models have a slight electrical sound because of our vocoder Griffin-Lim. Please pay more attention to the pitch and expressiveness of songs.
Chinese
1.在我心中曾经有一个梦
| GT Amateur | GT Profession | Pitch Predictor | DiffBeautifier | |
|---|---|---|---|---|
| wav |
2.再没有恨,也没有了痛
| GT Amateur | GT Profession | Pitch Predictor | DiffBeautifier | |
|---|---|---|---|---|
| wav |
3.你总说毕业遥遥无期转眼就各奔东西
| GT Amateur | GT Profession | Pitch Predictor | DiffBeautifier | |
|---|---|---|---|---|
| wav |
4.东边牧马,西边放羊
| GT Amateur | GT Profession | Pitch Predictor | DiffBeautifier | |
|---|---|---|---|---|
| wav |
5.生命已被牵引潮落潮涨
| GT Amateur | GT Profession | Pitch Predictor | DiffBeautifier | |
|---|---|---|---|---|
| wav |
6.明天你是否还惦记曾经最爱哭的你
| GT Amateur | GT Profession | Pitch Predictor | DiffBeautifier | |
|---|---|---|---|---|
| wav |
7.野辣辣的情歌就唱到了天亮
| GT Amateur | GT Profession | Pitch Predictor | DiffBeautifier | |
|---|---|---|---|---|
| wav |
8.用我们的歌换你真心笑容
| GT Amateur | GT Profession | Pitch Predictor | DiffBeautifier | |
|---|---|---|---|---|
| wav |
English
9.Because when the sun shines, we’ll shine together. Told you I’ll be here forever
| GT Amateur | GT Profession | Pitch Predictor | DiffBeautifier | |
|---|---|---|---|---|
| wav |
10.Baby cause in the dark, you can’t see shiny cars
| GT Amateur | GT Profession | Pitch Predictor | DiffBeautifier | |
|---|---|---|---|---|
| wav |
11.Together we’ll mend your heart
| GT Amateur | GT Profession | Pitch Predictor | DiffBeautifier | |
|---|---|---|---|---|
| wav |
12.I said: No one has to know what we do
| GT Amateur | GT Profession | Pitch Predictor | DiffBeautifier | |
|---|---|---|---|---|
| wav |
13.Wildest dreams
| GT Amateur | GT Profession | Pitch Predictor | DiffBeautifier | |
|---|---|---|---|---|
| wav |
14.That we can baby, we can change and feel alright
| GT Amateur | GT Profession | Pitch Predictor | DiffBeautifier | |
|---|---|---|---|---|
| wav |
15.Standin’ in a nice dress Starin’ at the sunset, babe
| GT Amateur | GT Profession | Pitch Predictor | DiffBeautifier | |
|---|---|---|---|---|
| wav |
16.Said I’ll always be a friend, took an oath. I’am stick it out till the end
| GT Amateur | GT Profession | Pitch Predictor | DiffBeautifier | |
|---|---|---|---|---|
| wav |